How to Design a Practical Type System to Maximize Reliability, Maintainability, and Productivity in Software Development Projects
Part 1: What, Why, and How?
|
First Published |
2023-10-03 |
|
Author |
Christian Neumanns |
|
Editor |
Tristano Ajmone |
|
License |

Introduction
A type system is a fundamental and essential part of every programming language, and profoundly determines how code is written and maintained.
A well designed type system empowers developers to write code that is succinct, easy to understand, reliable, maintainable, and safe.
This is the first article of a series. The entire series aims to answer the following questions:
-
What is a practical type system?
-
Which features do we need, why do we need them, and what are their benefits?
-
Which features should not be supported (even if they are popular in modern programming languages)?
-
How does a practical type system impact the look and feel of source code?
-
Do we have already practical type systems?
The target audience of this series of articles consists of software developers interested in writing reliable, maintainable, and safe code, as well as programming language engineers.
What's a Practical Type System?
We'll have a look at many source examples demonstrating how a type system helps to write better code. But first we need to define the following terminology, which is used throughout the article: type, cardinality, type system, and practical type system.
Type
A type is a name for a set of values.
For example, many programming languages support a type named boolean. This type can hold two values: true, and false. Using the mathematical notation for sets, the set of elements is: {true, false}.
Cardinality
The cardinality of a type is the number of distinct values in its set of values.
For example, type boolean has a cardinality of 2, because there are two values: true and false.
As we'll see soon, cardinality plays a pivotal role in the design of a practical type system.
Type System
The role of a type system is to:
-
Provide predefined, native types that are always available (e.g.
string,number,boolean, etc.). -
Provide a set of mechanisms and rules that enable developers to define new, specific types needed in their software development projects.
For example, a type system enables us to create a record type named
product, with fieldsid,description, andprice. -
Define how different types work together (type compatibility, type conversions, etc.).
Practical Type System
Here is my definition of a practical type system:
A practical type system must fulfill two conditions:
-
The Easy! Condition
It is easy to:
-
define new types with the lowest possible cardinality
-
quickly understand types by looking at their definition in the source code
-
change and maintain types
-
-
The Fail Fast! Condition
Invalid values, type incompatibilities, and other type-related errors are detected immediately at compile-time, whenever possible.
If it's impossible to detect an error at compile-time then it must be detected as soon as possible at run-time.
— The PTS Design Rule
Henceforth, I will refer to the above definition as the PTS Design Rule, where PTS is an acronym for Practical Type System.
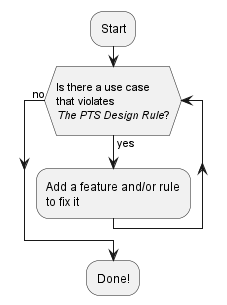
At first sight, the above definition might seem overly simplistic, because I am not mentioning important features such as static typing, semantic types, null-safety, error handling, immutability by default, etc. However, as we'll see later, the above definition is indeed all we need. In the following articles, we will simply apply the PTS Design Rule again and again, in order to discover the whole set of features and rules needed in a practical type system.
The flow chart below illustrates the process:
Why Do We Need It?
A good type system is like having compile-time unit tests.
— Scott Wlashin
In this section we're going to have a look at the following well-known (and not-so-well-known) benefits of a good type system:
-
increased expressiveness
-
more reliable and maintainable code
-
better support in IDEs and tools
-
more generic, reusable code
-
more efficient code
-
support for the First data, then code! approach
Note
Experienced programmers who are well aware of these benefits can skip to the last item.
Increased Expressiveness
Consider a function signature in a programming language with a type system that uses dynamic typing (e.g. JavaScript, Lisp, Lua, Python, Ruby). Here is an example shown in JavaScript:
function makeCoffee ( milk, sugar, quantity ) {
// body
}This code lacks expressiveness!
By just looking at the function signature we don't know how to use this function. There are a lot of relevant questions, such as:
-
What does the function do? What does it mean to 'make coffee'? What does the function return? Does it just produce a side effect and return nothing?
-
How should we use input argument
milk? Is it a boolean value, or the quantity of milk we want to add, or maybe an object describing the kind of milk and quantity? -
etc.
Better naming could help, but let's just look at the same function signature in a language that uses static typing (e.g. C, C++, C#, Go, Haskell, Java, Kotlin, Rust). The code below is written in Java:
CupOfCoffee makeCoffee ( boolean milk, boolean sugar, int quantity ) {
// body
}Much better!
We can clearly see that the function (or method in Java terminology) returns a CupOfCoffee object. If we need more information we can have a look at the definition of CupOfCoffee. If we use a modern IDE, we can chose goto definition from a context menu, and the IDE will immediately open the source code file (without the need for us to specify the file location).
We can also see that milk and sugar are boolean input arguments, hence we can infer that they indicate whether or not we want to add milk and sugar.
However, we don't know how to use quantity.
Is it the number of cups of coffee we want? Probably not, because the function returns a single CupOfCoffee, not a List<CupOfCoffee>
Is it an enumerated value (e.g. 1 = small size, 2 = medium, 3 = big)? Probably not, because then a Java enum type should have been used.
So what is the unit of quantity? Is it milliliters, centiliters, or maybe ounces?
And what is the valid range for quantity? Does the function return null if quantity is zero? What happens if we provide a negative value for quantity?
Note
The example above is not intended to suggest that "statically typed languages are superior to dynamically typed languages." Both approaches have their pros and cons, depending on the context. For example, dynamic typing can be more flexible in some cases. However, empirical evidence suggests that static typing clearly enhances reliability and maintainability, particularly in large-scale projects.
In a more expressive type system, all ambiguities vanish if we can write code like this:
fn make_coffee -> cup_of_coffee
in milk boolean
in sugar boolean
in quantity milliliters ( range = 50 .. 300 ) default: 200 !milliliters
// body
.Note
The above example is written in a new syntax that will be explained in subsequent articles.
More Reliable and Maintainable Code
Let's assume that makeCoffee is actually meant to work as shown in the last example: It takes boolean values for input milk and sugar, and an integer value ranging from 50 to 300 milliliters for input quantity.
Now suppose that Bob (a new programmer in the team) doesn't know this. To get 1 cup of coffee without milk and sugar he calls the function like this:
makeCoffee ( "no", "no", 1 )Questions: What will happen at compile-time? What at run-time?
These are critical questions!
The answer for both questions is that it depends on the type system!
Let's first look at what happens in JavaScript.
JavaScript is mostly implemented by an interpreter, so there is no compile-time (although a JIT compiler might be used at runtime to improve performance).
What happens at run-time?
The function expects a boolean value for milk. However, Bob provides a string value. JavaScript applies an error-prone technique called implicit type coercion, and uses so-called truthy and falsy values. For example, every non-empty string is considered to be truthy. Hence, if the function contains an if ( milk ) { ... } else { ... } statement, the then branch is executed if milk contains the string "no". So Bob will get a cup of coffee with milk, which is exactly the opposite of what he wanted!
The final result of all this is that Bob asked for a cup of black coffee (no milk and no sugar), but instead gets a mixture of milk, sugar, and 1 milliliter of coffee!
What about Java (and other statically typed languages)?
Fortunately, the above outcome doesn't happen in Java, because the type system doesn't allow it to happen. The statement:
makeCoffee ( "no", "no", 1 )... would immediately result in a compile-time error, because a string cannot be assigned to a boolean input argument.
That's exactly what we want! We want the type system to help us and report mistakes as soon as possible.
One could argue that the above sample code is just a funny toy example, only useful to entertain readers, and that nobody would write silly code like this. However, fact is that silly mistakes do happen in the real world. Practice shows that they happen all the time. Their probability increases significantly with the size and complexity of a project, and can be influenced by various factors such as domain complexity, expertise of the managers and developers, the amount of code to be written and maintained, the tools and processes used to detect and resolve bugs, and more.
For the sake of exercise, just imagine a bug like the above one in a complex software application that manages the manufacturing process of drugs. Producing a drug with the wrong ingredients isn't funny anymore. The bug can cause fatalities that could have been prevented by using a programming language with a better type system suited to write reliable code.
Here is my personal experience: Although I've been coding for a few decades now (and still love it), I'm still making silly mistakes. I make less mistakes than when I started to write code, but I'm still unable to write bug-free code. Some of my coding mistakes were not just 'silly' — they were 'very silly'. I need a type system that protects me (as far as possible) from shooting myself in my foot.
I guess I'm not alone.
Maybe there are some geniuses out there who are capable of writing code that is entirely free of bugs, but I'm not a member of such an elite group. I suspect that such individuals would be very rare outliers.
Consider, for example, a highly qualified software developer working on a space mission project. He or she would never force a 64-bit floating point number into a 16-bit signed integer value, without checking first if the value isn't to high, because that would be silly, right? Right, but that's exactly what caused the Ariane 5 rocket to explode in 1996. This is just one example in the Wikipedia entry List of software bugs with extremely serious consequences.
We all make mistakes, and that's OK. That's precisely why we need type systems capable of auto-detecting inevitable human errors, including silly ones.
Better Support in IDEs And Tools
A good type system enables an IDE to provide better editing support. Some example are:
-
automatic bug reporting at edit-time
-
better code completion
-
safe and automatic refactorings, such as renaming types
-
jump to the definition of a type
-
display all usages of a type
We all love these features because they greatly boost our productivity and make the process of writing and maintaining code a much more enjoyable experience.
Other tools (for example static code analyzers) can also use the type information available in the source or binary code and provide even more sophisticated features, such as detecting additional bugs and security issues, reporting and/or correcting coding style violations, or creating project-specific reports and statistics.
More Generic, Reusable Code
The ability to read type information at run-time (called introspection/reflection) enables us to write more generic, reusable code.
For example, if the element type of a collection can be inspected at run-time, it is possible to write general purpose utility functions that:
-
serialize collections into structured text or binary formats, such as JSON, XML, or PDML.
-
display collections as a table in a GUI — each attribute of the element type being a column in the table.
Note
This topic deserves a dedicated article in its own right, which I'm planning to publish at some future date.
More Efficient Code
A good type system enables the compiler to optimize the generated binaries, which results in:
-
smaller size of target code
-
faster execution time
1. Data; 2. Code
There is another, less known argument in favor of a practical type system.
Smart programmers tell us that we should always start by defining the data structures and their relationships, before writing code. We should first define the data, then write code.
1. Data
2. Code
Here are a few quotes from well-known people who know what they are talking about:
I’m a huge proponent of designing your code around the data, rather than the other way around, and I think it's one of the reasons git has been fairly successful.
Bad programmers worry about the code. Good programmers worry about data structures and their relationships.
— Linus Torvalds, creator of Linux and Git; Git mailing list, 2006-07-27
Note
For more details about the data structure used in Git, see: comments on Hacker News (especially the first one by cmarschner), and Linus's first README file that describes the data structure (in typical Linus style).
Rule of Representation: Fold knowledge into data so program logic can be stupid and robust.
Data dominates. If you’ve chosen the right data structures and organized things well, the algorithms will almost always be self-evident. Data structures, not algorithms, are central to programming
— The Art of Unix Programming, by Eric Steven Raymond
Rule of Representation in section Basics of the Unix Philosophy
Note
You can find more quotes in section Data Design of my article Fundamental Pragmatics for Successful Software Developers (April 2018).
Well designed data structures lead to simpler and more maintainable code, less bugs, better performance, and less memory consumption.
The difference can be striking, to the extent that it may determine the success or failure of a project.
Note
The concept of Data-driven programming is related to, but not the same as the above 1. Data; 2. Code rule.
Recognizing that defining data is the first step, we need to ask:
What do we use to define data?
The answer depends, of course, on the software architecture and development environment, but more often than not, we use the type system of the programming language to define the data structures and their relationships. A well suited type system is therefore an essential instrument that allows us to define the data in a succinct, expressive, precise, reliable, and maintainable way. Hence, the type system often plays an important role at the start of a new software project, especially if many different data structures are involved.
What's more, well designed and maintainable data plays an important role during the software development and maintenance cycle. For example, new software developers joining the team at a later stage will be able to understand the internal workings of the application faster if they can look at type definitions that are succinct, expressive, and precise, so that they can quickly understand which values are allowed.
Fred Brooks puts it this way (text within brackets added for clarification):
Show me your flowcharts [code] and conceal your tables [data structures], and I shall continue to be mystified. Show me your tables [data structures], and I won’t usually need your flowcharts [code]; they’ll be obvious.
— Brooks, F. P. (1995). The Mythical Man-month: Essays on Software Engineering. Pearson Professional.
How Does it Work?
To get the gist of PTS, let us first look at a real-life example to clearly demonstrate what we want to achieve.
Then we'll have a closer look at the essential Fail Fast! condition of the PTS Design Rule.
Example
Suppose we want to assign quality levels to products. There are five levels:
worst, bad, medium, good, and best.
In Java, we can define an enum type Quality as follows:
public enum Quality {
WORST, BAD, MEDIUM, GOOD, BEST // Note: In idiomatic Java,
// enum values are defined in uppercase letters.
}
We can immediately agree that it's easy to define type Quality. We are able to express what we want with a minimum of succinct code.
Hence the first condition (the Easy! condition) of the PTS Design Rule is fulfilled: It is easy to define, understand, and maintain our type.
Now let's verify the second condition (the Fail Fast! condition): "Invalid values, type incompatibilities, and other type-related errors are detected immediately at compile-time, whenever possible."
A valid value can be assigned to a variable of type Quality as follows:
Quality productQuality = Quality.GOOD;
Let's try to assign an invalid value:
Quality productQuality = Quality.QUITE_GOOD;
The Java compiler immediately reports an error, because QUITE_GOOD is an invalid value:
Tests.java:15: error: cannot find symbol
Quality productQuality = Quality.QUITE_GOOD;
^
symbol: variable QUITE_GOOD
location: class Quality
Even better, if we use an intelligent IDE, we get an error at edit-time, which is great. In IntelliJ™ IDEA (an awesome IDE for Java projects), the screen looks like this (note the suggestions to fix the bug):

This is exactly what we want!
Let's try another kind of error:
Quality productQuality = "GOOD";
Again, the compiler immediately reports an error, because we are trying to assign a value of type String to a variable of type Quality.
The Fail Fast! condition is clearly fulfilled too.
We can conclude that type Quality is a good example to demonstrate how a practical type system should work. It's easy to define, understand, and maintain the type (condition 1), and the compiler catches all type errors (condition 2). Moreover, if we use an intelligent IDE, all bugs are immediately reported at edit-time, and the IDE displays helpful messages to fix the bug. Awesome!
Type Quality is fully compliant with the PTS Design Rule.
Our aim is to achieve this level of excellence for all types. However, that's quite challenging, as we'll see in the upcoming articles of this series.
Fail Fast!
Note
Readers familiar with the important Fail Fast! principle can skip this section.
While the Easy! condition (the first condition of the PTS Design Rule) is easy to grasp, let's look at a simple example illustrating the full meaning of the Fail Fast! condition (the second condition of the PTS Design Rule):
Invalid values, type incompatibilities, and other type-related errors are detected immediately at compile-time, whenever possible.
If it is not possible to detect an error at compile-time then it must be detected as soon as possible at run-time.
— PTS Fail Fast! condition
Suppose that the temporary file temp/secret/passwords.txt (containing passwords in plain text!) needs to be deleted in a portable application (running on Linux, MacOS, and Windows), but the source code accidentally uses an invalid : character in the file path:
fileToDelete = "temp/secret:passwords.txt"
^This is a clear case of invalid data.
Note
While character : is an invalid character in Windows, it is not invalid on Linux, even though this character is used as a path separator on Linux. For the sake of this example we assume that : is invalid in a file path, even if the application runs on Linux.
An interesting question arises: What will happen?
Answer: It depends on the type system!
In a primitive type system, IO errors can be ignored. If the source code doesn't explicitly test for an IO error, then no error is generated, neither at compile-time, nor at run-time. File temp/secret/passwords.txt will simply not be deleted, and the application will happily continue execution, as if exposing passwords in a plain text file is not a big deal, and everything is OK.
In many programming languages, this bug would lead to a "file not found" run-time error later when the application tries to access the file. However, "later" in this context might mean "much later." Hence, if the application crashes or is interrupted before executing the instruction that is supposed to delete the file, then the file will not be deleted and no error will be generated.
In a better type system, an "invalid file path" run-time error occurs as soon as the assignment fileToDelete = "temp/secret:passwords.txt" is executed (i.e. before accessing the file on the OS).
An ideal type system reports the bug at compile-time.
Even better, if a modern IDE is used to write the code, the bug is reported at edit-time, and can immediately be fixed within seconds!
In a perfect world, this immediate feedback would exist for all bugs.
But we are not there yet. The best we can achieve with a practical type system is to auto-detect as many bugs as technically possible.
Here are the times at which a bug can be detected, listed from best to worst:
-
Edit-time
-
Compile-time
-
Immediately at run-rime
-
Later at run-rime
-
Never
By now, it should be clear that the goal of PTS is to catch as many bugs as possible at compile-time (or edit-time if an intelligent IDE is used).
If a bug cannot be detected at compile-time, it should be detected as soon as possible at run-time.
Let's now suppose that the buggy file path (temp/secret:passwords.txt) is not hard-coded, but read from a config file. In that case, the compiler can't report a bug. The error in the config file should therefore be caught immediately when the path is read from the file (and not just later when the file is deleted). A subsequent article will show data input validation can be facilitated by the type system.
Note that bugs detected at run-time can be caught by unit tests. This helps to eliminate bugs before the application goes into production. Therefore, good support for unit tests (beyond the scope of this article) is an essential feature in any programming language, even if the language has an advanced type system. A good type system doesn't make unit tests dispensable. The slogan "If it compiles, it works!" is just wishful dreaming. No compiler in the world can detect bugs like using the wrong formula to compute the area of a circle. We need unit tests to detect bugs like that.
Note
You can read more about the important Fail-Fast! principle in my article Introduction to the "Fail fast!" Principle in Software Development.
The PTS Coding Rule
Pretty much all programming languages allow us to write reliable code.
But practice shows that writing reliable code is challenging in many programming languages, and often requires boilerplate code (as will be shown in subsequent articles). It largely depends on the type system.
As seen already, an essential role of a practical type system is to facilitate (as far as possible) the process of writing and maintaining reliable code.
However, a type system cannot force us to write reliable code in all cases. It can only do so to a certain extent.
For example, a type system cannot force us to create a dedicated type ISBN that only allows valid values according to the ISBN standard. If we decide to use a simple string for ISBNs, thereby allowing nonsense values like @#$, malicious values like <script>alert("Hi! You've been hacked")</script>, and other wicked values, then there is nothing the type system can do about it.
Maximum reliability can only be achieved if the programmer actually uses the available type system mechanisms to define safe types. Therefore, besides the PTS Design Rule, we also need the following simple PTS Coding Rule:
All data types in a software project should have the lowest possible cardinality.
— The PTS Coding Rule
The above rule is especially important for library/framework developers, since these packages are typically used by lots of other developers who use the API like a black box. Users of standard libraries and third-party libraries should be protected against accidental misuses as far as possible.
Whole classes of bugs can easily be prevented if a package uses safe types with the lowest possible cardinality.
Besides disallowing invalid values, dedicated safe types also provide protection against semantic type errors.
Consider the following Java code:
String s1 = "Hello" // declare 's1' of type 'String', with value "Hello"
String s2 = s1 // declare 's2' of type 'String', with same value as 's1'Is there a bug in this code?
Well, there is no obvious bug, and the code is surely correct for the compiler.
Now let's just change the variable names:
String message = "Hello"
String book_ISBN = messageThe code is now obviously wrong ("Hello" is an invalid ISBN), but the bug can't be detected by the compiler.
However, the bug can easily be prevented by using a dedicated and safe type ISBN, instead of a String:
String message = "Hello"
ISBN book_ISBN = message
^^^^Much better! The compiler can immediately report the bug, because type String is not compatible to type ISBN. Moreover, the compiler of an advanced type system would generate an error for an assignment like book_ISBN = "Hello", because "Hello" is an invalid ISBN.
Note
An article published at a later date will explain how safe types like ISBN are created and handled in PTS.
We can conclude that we need both, the PTS Design Rule and the PTS Coding Rule. They go hand in hand. The Design rule is meant to be applied by language designers/implementors, while the Coding rule is for software developers.
Conclusion (So Far)
A practical type system makes code
easier to read and write
more expressive and more understandable
more reliable, more maintainable, and safer
smaller and faster
As a result it
increases software quality and reliability
decreases development time and costs
makes coding more enjoyable
A practical type system matters
What's Next?
In the next article, we'll have a look at PTS goals and non-goals, the history of PTS, core types, and 'features' that should not be supported in a practical type system.
Then, we'll apply the PTS Design Rule again and again, in order to discover all PTS features and rules needed to help writing reliable, maintainable, and safe code in less time.
We'll also have a look at many source code examples to illustrate how source code could look like in a language that implements PTS.
Links to All Articles in the Series
The following list will be updated after publication of each article in the series.
Acknowledgments
Many thanks to Tristano Ajmone for his useful feedback to improve this article.